
Overview
Project: WyrdFold, a self-hostable, bring-your-own-key job-search platform. It polls job boards against the roles you are targeting, grades every posting for fit with an LLM pipeline, and tailors resumes and cover letters for the matches worth pursuing.
Role: Solo Developer
Duration: May 2026 - present
Purpose: Turn the job search from manual board-scrolling into a graded pipeline. This is the project where I went from owning the frontend to owning the whole stack: a Next.js web app, a FastAPI matching service, a Postgres schema, and a production LLM pipeline with the cost and quality controls that running one in production actually demands.
The problem
Searching for a senior role means scanning hundreds of near-identical postings, guessing which ones fit, and rewriting a resume for each one that does. The signal is real but buried, and the work of surfacing it is exactly the kind of repetitive judgment a language model is good at, provided you can afford to run it and trust what it returns.
WyrdFold started inside this portfolio's monorepo as a job-pipeline experiment, then outgrew its host. It needed a Python service for the matching work, its own deploy cadence, and a schema that had nothing to do with a marketing site. So I extracted it into a standalone repo and rebuilt it as a product: source-available, self-hostable, and designed so a single user running it on their own Supabase project and their own LLM key gets the full system.
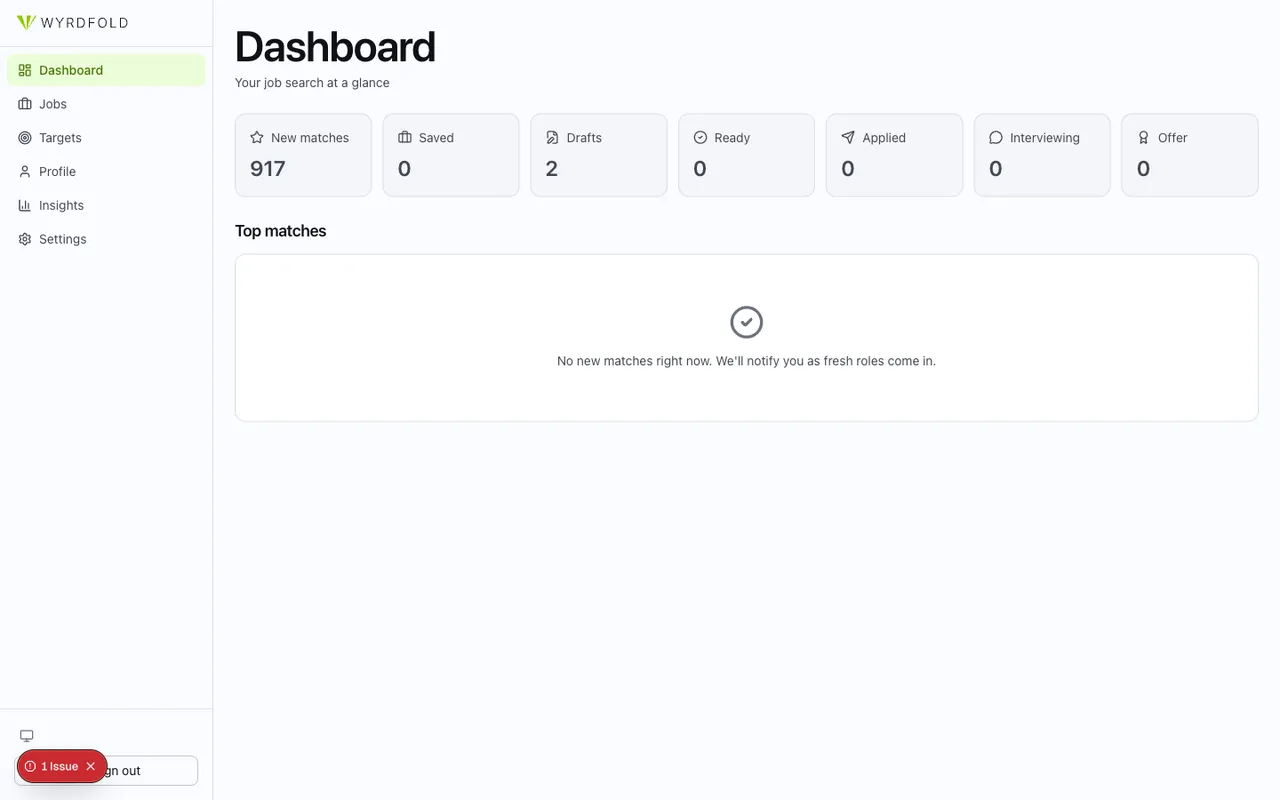
The architecture
Three deployables cooperate through Supabase. The browser only ever talks to the Next.js app, which acts as a backend-for-frontend and proxies to the Python service; the FastAPI service owns the LLM work and the polling.
The web app is Next.js 16 on Vercel; the matching service is FastAPI on Railway, shipped as a Docker image. Auth is magic-link only through Supabase, and the database is Postgres with pgvector for embeddings. The web app forwards the user's Supabase JWT to the API as a Bearer token, and the API verifies it against Supabase's JWKS endpoint rather than trusting the proxy. The design system is the same @danieljoffe/shared-ui package this portfolio uses, consumed from npm, so the two products stay visually consistent without sharing a repo.
Every external dependency past Supabase degrades gracefully. Brave Search for source discovery, Voyage for embeddings, Twilio for SMS alerts, Sentry for error tracking: leave any of them unset and the feature is skipped or mocked. The API even boots with LLM_PROVIDER=mock so a contributor can run the whole thing without spending a cent, though matching quality is the product, so a real key is the point.
The matching pipeline
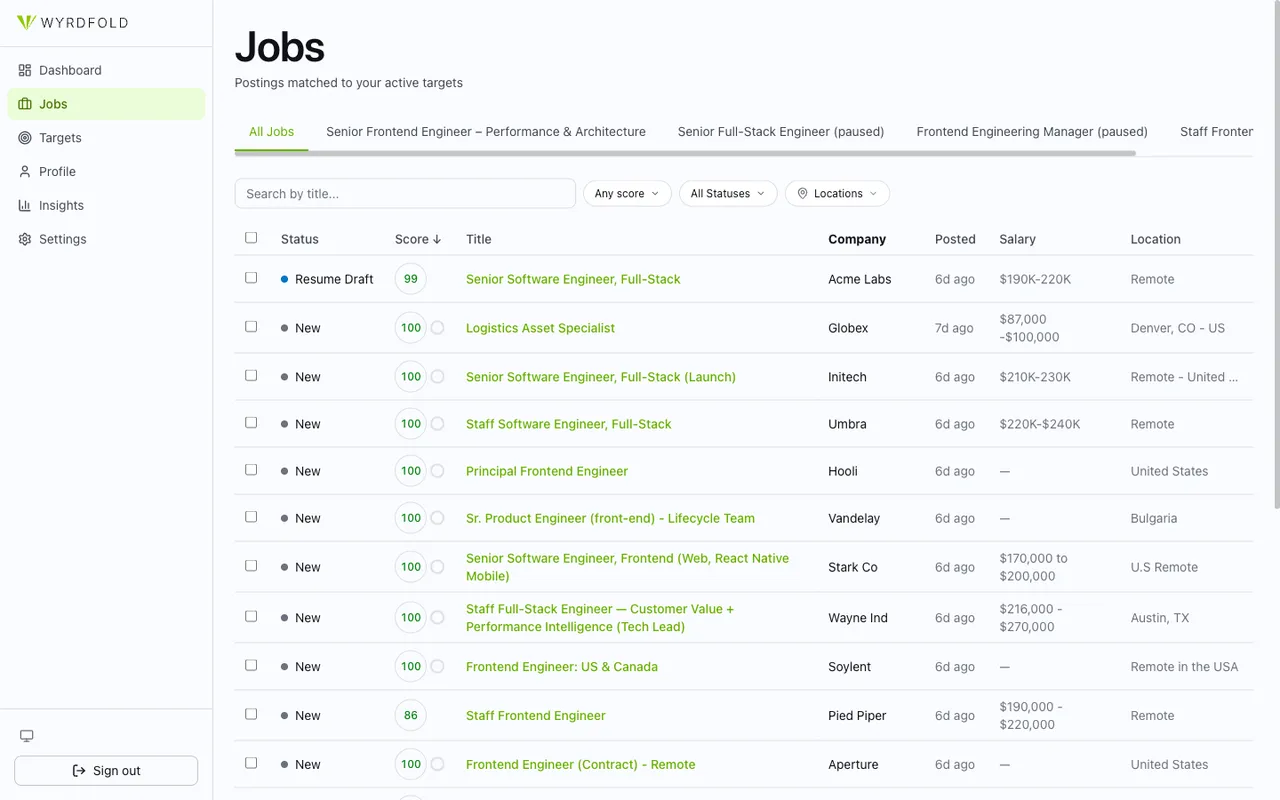
Grading every posting with a full LLM call is the obvious design and the wrong one. Most postings are off-target on the title alone, and paying for a deep reasoning pass on a job that was never a fit burns budget for no signal. So matching runs in two phases: a cheap title-triage pass gates an in-depth fit grade. Only postings that survive triage reach the expensive call.
The deep grade scores four axes with weights the user can tune: technologies, domain, seniority, and title. The result is not a black-box number. Each job carries a score breakdown by component plus an LLM analysis with reasoning, the skills it found missing, and a per-axis read. A job can sit at the top of the list with a transparent "near-perfect technical match, only gap is one backend technology unlikely to block a frontend-focused role" rather than an unexplained 99.
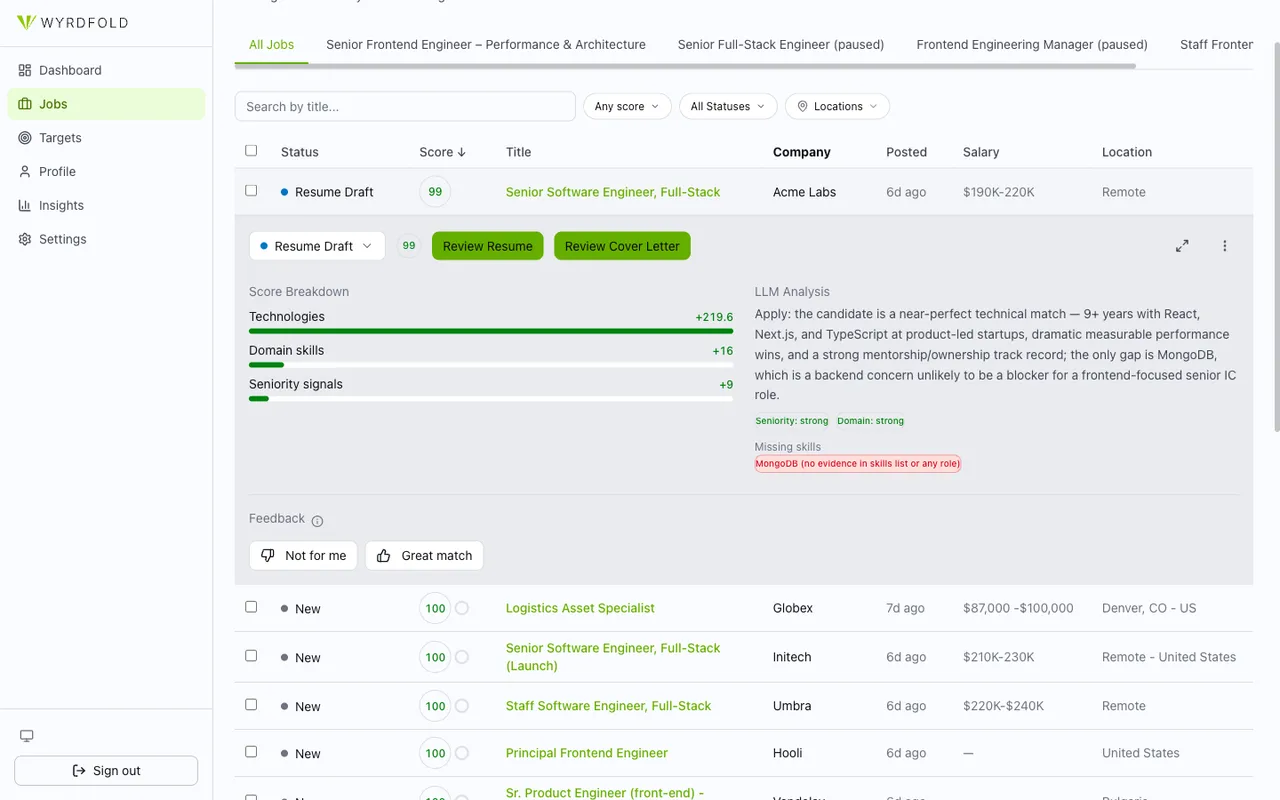
The full list view scores every polled posting against the active targets, with score, salary, and location inline, filterable by score and status. The targets themselves are first-class: role profiles new jobs are graded against, so the same posting can rank differently for a "Senior Frontend" target and a "Full-Stack" one.
Operating an LLM pipeline in production
The hard part of shipping LLM features is not the prompt. It is everything around it: cost, reproducibility, and what happens when a generation fails while a user is watching.
Versioned prompt caching. LLM output is cached, and the cache key includes a prompt_version. When I change a prompt, the version bumps and old entries miss by construction, so a prompt edit never silently serves stale reasoning from the previous wording. Without the version in the key, the cache becomes a correctness bug the day you improve a prompt.
Shadow runs before flipping. A prompt change does not ship to users on merge. It ships behind a flag and shadow-runs against the old prompt for at least a week, so I can compare the two on real postings before flipping. Prompt quality is not unit-testable; the only honest evaluation is the live distribution.
Cost guardrails in three layers. Per-user budgets (hourly, daily, monthly), a global daily circuit breaker that defers all LLM work once it trips while still ingesting jobs, and provider-side spend caps set just above the global cap as a final backstop. The poller emits Sentry warnings at 80% of the daily cap and an error when the breaker trips, so a cost run-up is an alert, not a surprise invoice.
Failure is a row, not a log line. User-visible async tasks carry a timeout and persist their error to a column, and the frontend offers a retry. A generation that dies server-side and logs a stack trace leaves the user staring at a spinner; a persisted error and a retry button is the difference between a product and a demo.
Resume tailoring and insights
Tailoring is grounded in a master experience document with versioning and a document-health indicator, so generated resumes draw from real history rather than inventing it. The profile flags gaps to fill and exports finished documents to DOCX.
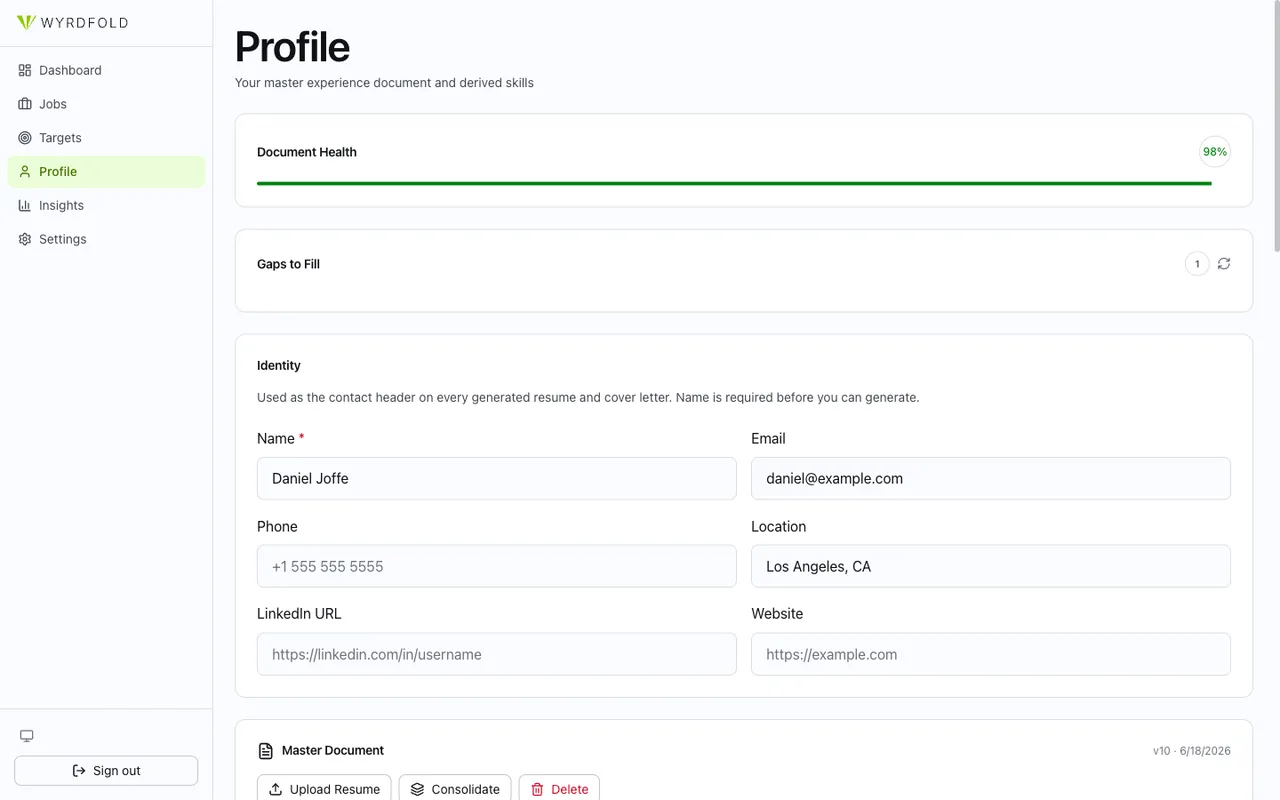
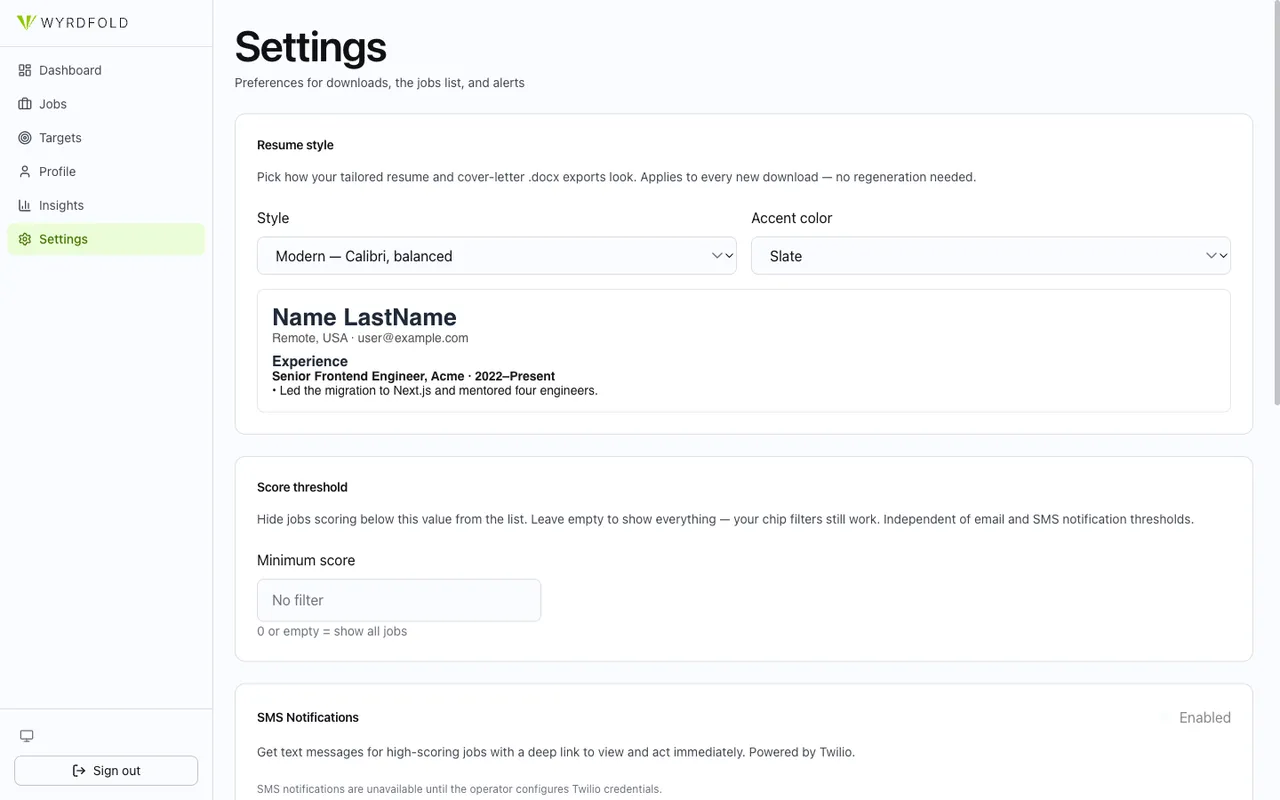
Settings expose the levers that matter for a self-hoster: resume style and accent, the score threshold that decides what counts as a match, and SMS notifications through Twilio. The defaults are sane; the knobs are there when you want them.
The result
WyrdFold is live, owned solo, and self-hostable end to end. A single user with a Supabase project and one LLM key gets target-driven discovery, two-phase graded matching with transparent per-axis breakdowns, a tracked pipeline from saved to offer, and grounded resume tailoring. It is source-available under a license that keeps self-hosting genuinely free.
What is still in flight is honest to name: source coverage keeps expanding board by board, the insights dashboards get richer as a real pipeline accumulates history, and the shadow-run evaluation loop is a standing practice rather than a finished feature. The cost and observability scaffolding is built precisely so that flying the rest in is safe.
Takeaway
The frontend was never the risky part. What made WyrdFold a full-stack project was the unglamorous machinery around the model: a cache key that knows which prompt produced it, a circuit breaker that bounds the bill, and a retry path for the generation that failed while someone watched. Ship those first, and the LLM feature is a product instead of a liability.