
This tool has been retired
If you landed here from /audit, the free audit tool isn't live anymore; this
is the case study of how I built it and why I shut it down. The honest
postmortem is at the end.
Overview
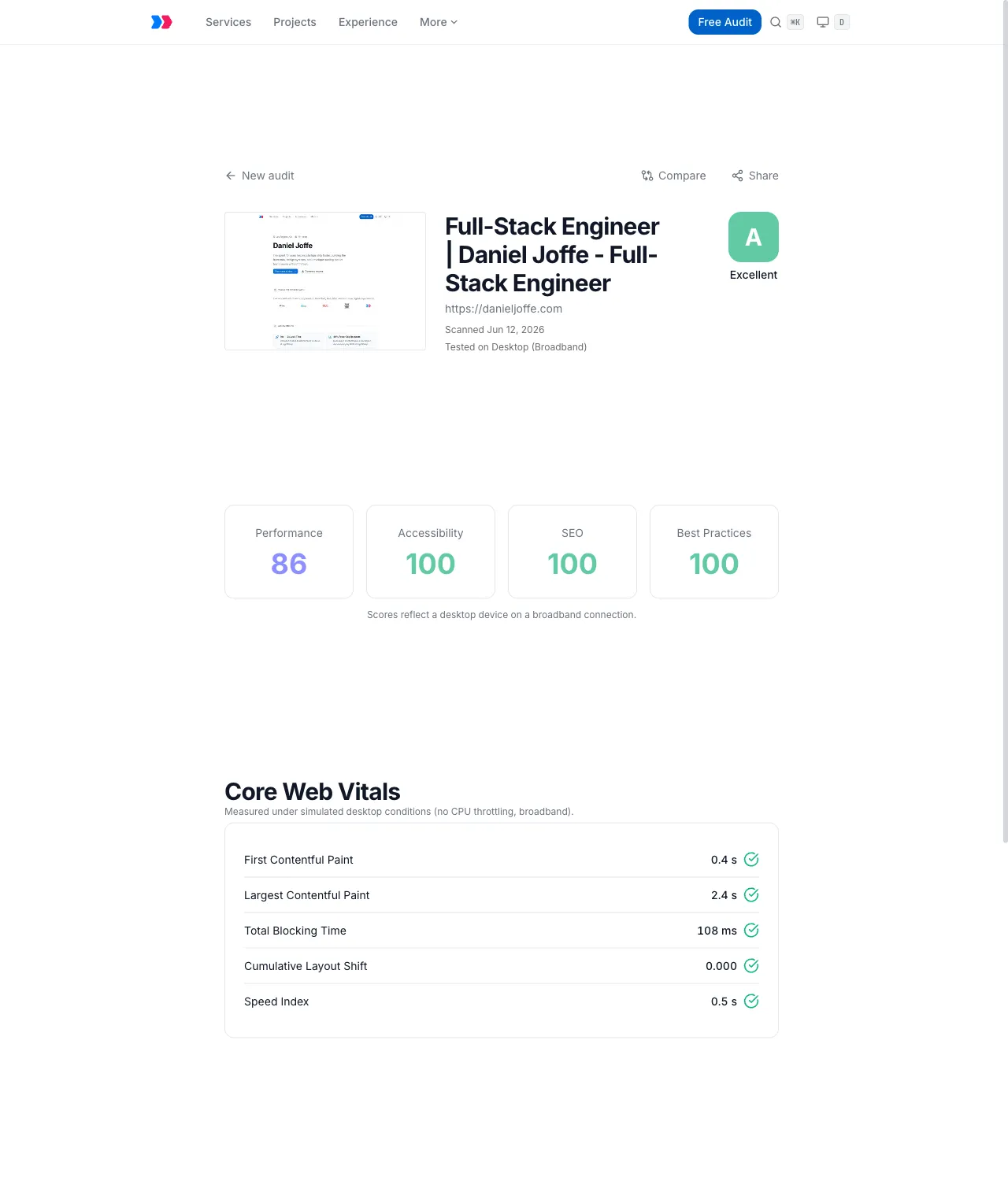
Project: Free public website audit tool: paste a URL, get a graded performance, accessibility, and SEO report in about 30 seconds
Role: Solo Developer
Duration: February - April 2026
Purpose: Generate consulting leads by giving prospects a concrete, free diagnosis of their site, backed by a FastAPI scan service running Lighthouse and axe-core in Docker
The hypothesis
The theory was textbook lead-gen: a prospect runs a free audit, sees a C grade and twelve concrete issues, and books a call with the person who just diagnosed them. No signup wall, no email gate; the report had to be good enough that handing over an email for the PDF version felt like a fair trade and not a toll.
That meant the tool couldn't be a marketing veneer over PageSpeed Insights. It had to run real Lighthouse and real axe-core scans against arbitrary URLs, on demand, from an anonymous public form, and that's what turned a marketing experiment into a systems problem: untrusted input, headless Chrome in production, async jobs that outlive the HTTP request that kicked them off, and abuse prevention with no user accounts to hang it on.
Architecture
Three pieces talk to each other through Supabase. The browser only ever talks to Next.js, and the scan service only ever talks to Postgres.
The Next.js route validates the URL, checks the rate limit, inserts a scans row with status pending, and fires the scan service inside after() so the response returns right away. The FastAPI service answers 202 Accepted, runs the scan from an internal queue, and writes scores, Core Web Vitals, parsed issues, and a computed grade back to the same row. The results page polls a status endpoint until the row flips to completed or failed.
The tool is fully anonymous, so there are no user rows to scope writes against. Both writers (the Next.js route and the Python service) use the Supabase service-role key, which never leaves a server, and the browser can't reach Postgres at all; every read goes through a Next.js API route that shapes and caps the output.
The scan pipeline
The FastAPI service runs one scan at a time from an in-process asyncio queue. That serialization is on purpose: Lighthouse uses global performance marks, and two concurrent runs in the same process corrupt each other's traces. Within a single scan, though, Lighthouse (a Node subprocess) and axe-core (injected into a Playwright page) share nothing, so they run in parallel:
lighthouse_task = asyncio.create_task(_run_lighthouse(url, device))
axe_task = asyncio.create_task(_run_axe_and_capture(url, device))
lighthouse_result, axe_results = await asyncio.gather(
lighthouse_task, axe_task, return_exceptions=True
)A persistent browser pool keeps one Chromium process alive across scans, with a fresh browser context per scan for isolation and an idle shutdown after 30 minutes. The pooling has its own write-up in the API performance case study.
Grading is a weighted blend of the four Lighthouse categories: performance 40%, accessibility 25%, SEO 20%, best practices 15%, mapped onto A through F. The weights encode an opinion (slow sites lose visitors faster than sites with missing meta tags), and keeping them in one function meant the public report, the admin dashboard, and the aggregate insights pages could never disagree about what a B means. URL normalization, validation, and the grading types live in a shared library (@danieljoffe.com/shared-audit), so the Next.js side and the report UI agree with the database by construction.
Scanning arbitrary URLs safely
A public form that makes a server fetch any URL is an SSRF hole unless you treat it like one. Validation runs twice, once on each side of the trust boundary. The Next.js route rejects non-HTTP protocols, localhost, and literal private IPs before a row is ever created; the Python service repeats the check and then goes a step further, DNS-resolving the hostname and rejecting any address in a private, loopback, or link-local range. Without that second pass, metadata.evil.com resolving to 169.254.169.254 would slip right past a literal-IP blocklist and point Lighthouse at internal infrastructure.
Rate limiting needed no extra infrastructure because every scan is already a Postgres row with a hashed IP:
const { count: recentScans } = await supabase
.from('scans')
.select('id', { count: 'exact', head: true })
.eq('ip_hash', ipHash)
.gte('created_at', oneHourAgo);Ten scans per IP per hour, with a mobile-plus-desktop comparison counting as two. The same table doubles as a cache: a completed scan of the same normalized URL and device within the last hour comes back instantly instead of burning another Chromium run. One table, three jobs: persistence, rate limiting, and caching. Vercel's bot detection screens the endpoint before any of this runs, and the scan service itself only accepts requests that carry an API key, behind TrustedHostMiddleware.
Failure went in a row, not a log line
Scans fail constantly out in the wild: bot walls, expired certificates, redirect loops, 45-second page loads. Early on those surfaced as raw Playwright errors (ERR_HTTP2_PROTOCOL_ERROR) that meant nothing to a visitor and weren't much help to me either. The fix had two halves.
First, a pattern table maps the raw browser and network errors to plain, human messages: "This site blocked our scanner. It uses bot detection that prevents automated audits." Second, every failure gets persisted to the error_message column on the scan row, so the polling frontend can render the explanation and offer a retry instead of spinning forever. A background job that someone's sitting there waiting on needs a timeout, a persisted error, and a retry path, and logging the exception server-side gives you none of those.
The subtlest bug in the whole project lived here too. PostgREST UPDATEs silently touch zero rows when the id doesn't exist, so one misconfigured SUPABASE_URL let scans run for a full 20 seconds before dying at a foreign-key constraint with a baffling error. The fix was a guard that checks the UPDATE actually hit a row when the scan is marked running, and fails fast with a message that names the likely config mismatch.
Shipping headless Chrome
The Dockerfile is where most of the project's scar tissue lives. The service builds on the official Playwright Python image because a hand-rolled uv-plus-Debian base with apt-installed Chromium kept segfaulting on launch in Railway. From there it's a pile of small fixes: Node.js installed for the Lighthouse CLI (the Python image ships none), Python pinned to 3.11 so uv doesn't grab a version with no prebuilt wheels for the Supabase client's dependencies, and CHROME_PATH pointed at whichever Chromium binary the base image actually ships, probed with find because the layout shifts between image versions. The image tag has to match the playwright version in uv.lock exactly, or the package refuses to launch a mismatched browser build.
None of that is glamorous, but all of it is the difference between a demo and a service that survives a platform redeploy.
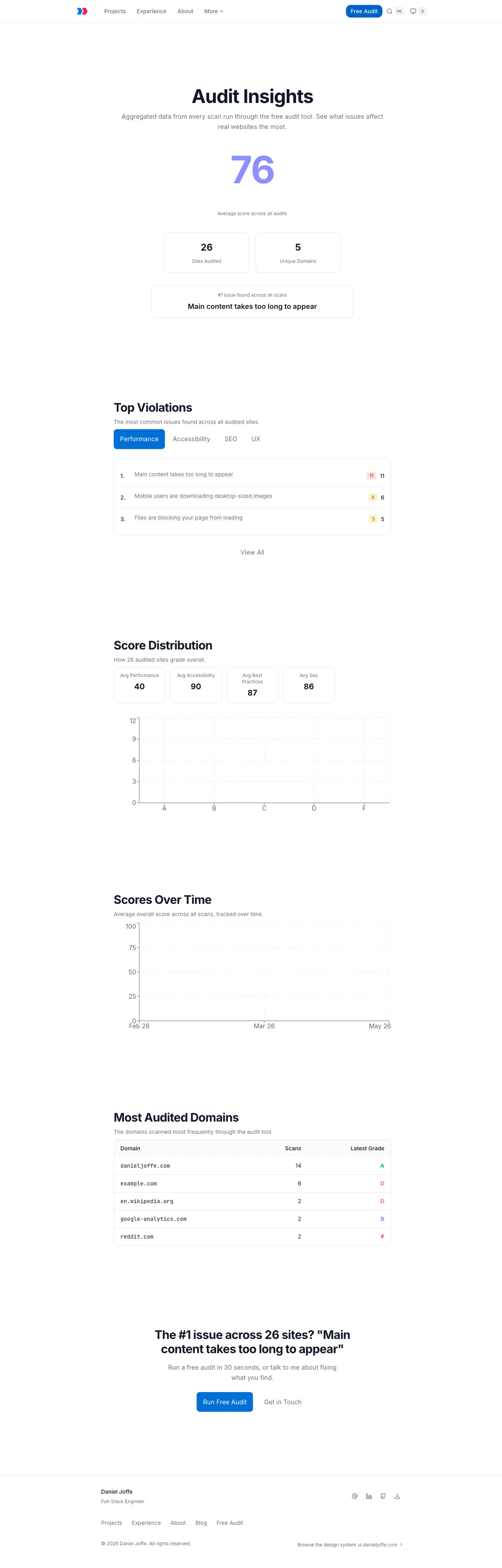
What the leads table taught me
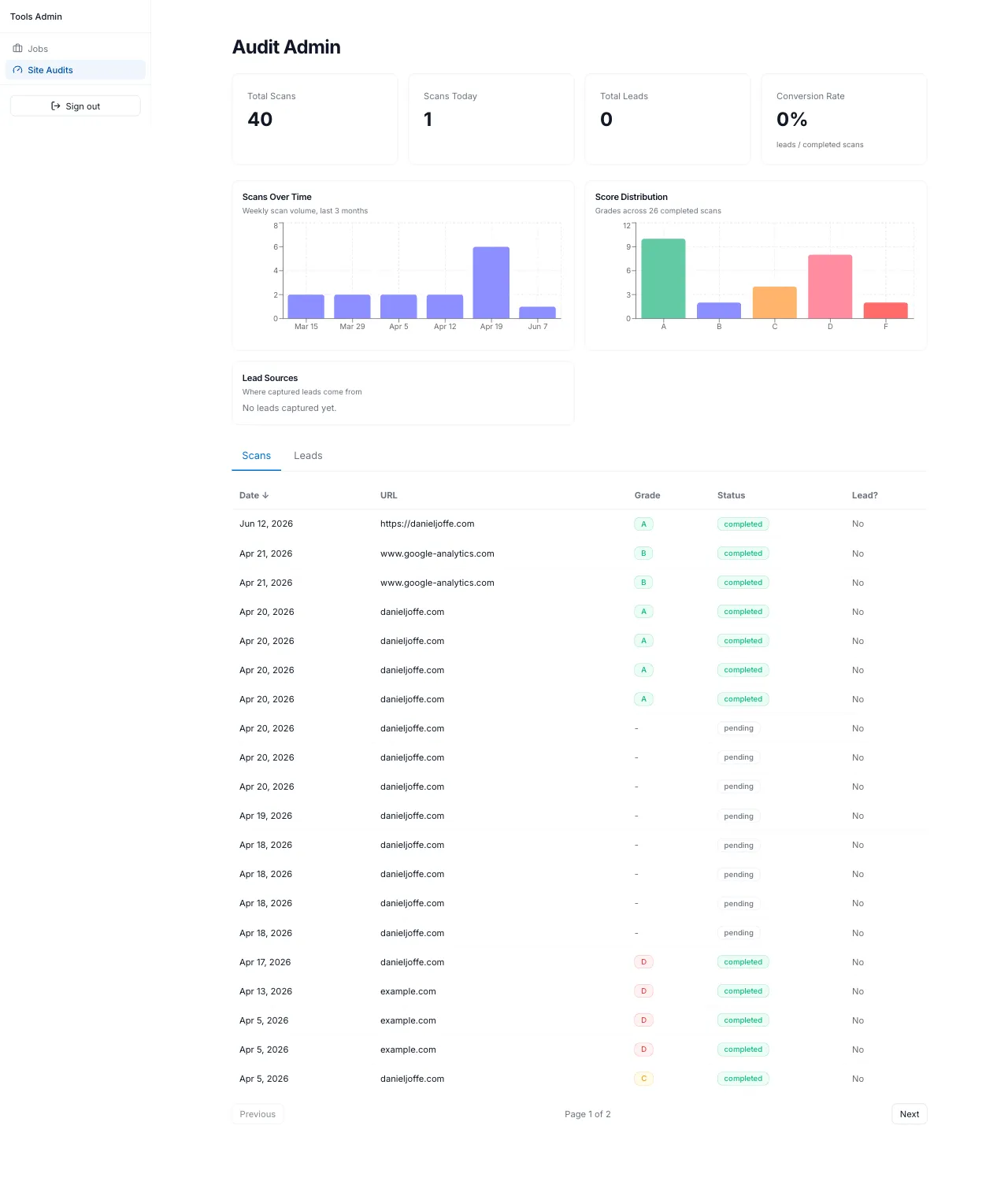
The engineering worked. Scans completed, the grades matched manual Lighthouse runs, the aggregate insights pages built real charts from anonymized scan data, and the admin dashboard tracked every scan and lead source. The leads table stayed close to empty.
The hypothesis had a silent dependency I never tested: people have to find the tool before it can convert them. I'd built the product end of the funnel and assumed the top would fill itself through search; it didn't, and it was never going to in a niche where the established tools own every relevant query. An inbound tool with no distribution channel is just a backend with excellent test coverage and no traffic.
I'd make most of the same engineering calls again, at half the polish. The browser pool, the SSRF hardening, and the error taxonomy were worth building well; the comparison mode and the insights charts were polish on a funnel with nothing flowing through it. The honest sequencing is to prove the channel with something embarrassingly small first, then earn the engineering.
Takeaway
I treat distribution as part of the spec now, not something that falls out of build quality on its own. A tool nobody finds fails the exact same way as a tool that doesn't work, and you only get to see the difference in the postmortem.